
Math guys??: Mathematics of streaks
Oh no, not at all! Say it isn't so; I'm crushed! Surely, pure stats must reveal nothing but absolute truth without regard for any fundamentals inherent in what is being measured:Quote: QFIT"There are three kinds of lies: lies, damned lies, and statistics." --Benjamin Disraeli
One must be extremely careful when presenting stats as misapplication of statistical theory can result in absurdity.
Spurious Correlations
Quote: Tylervigen @SpuriousCorrelations
US spending on science, space, and technology
--correlates with--
Suicides by hanging, strangulation and suffocation
Number of people who drowned by falling into a pool
--correlates with--
Films Nicolas Cage appeared in
Per capita cheese consumption
--correlates with--
Number of people who died by becoming tangled in their bedsheets
...<MORE>...
Quote: DrawingDeadNumber of people who drowned by falling into a pool
--correlates with--
Films Nicolas Cage appeared in
Well, everyone knows that one is a valid correlation.
Using a decision tree or similar. There are only 14 times (of the 16 potential "4" flip outcomes) that one or more heads can occur in first 3 spots in any 4 flip sequence. Thus we disregard TTTT and TTTH. Agreed?
In the remaining 14 scenarios that are eligible to have a head following a head only approx 40% do so.
https://sinews.siam.org/Portals/SiNews2/EasyDNNNews/thumbs/383/117HotHandsTable.JPG
***For this particular example*** Thus a head = 50% is not true statement once we measure all instances that meet the qualifier of how often does a "head follow a head when one or more of the first 3 flips is a head".
It's the taking of TTTT and TTTH out the equation is why we end up with a shortfall of measurable tails.
**Anyhow the only good of this type of insight (it seems) is that the researchers found that those who could hit free throws near their typical ft% even after several makes in a row actually are showing evidence of a hot hand; just like 50% heads isn't expected under the above coin flip restriction, but if found (it wasn't) it'd defy probable expectation
One post you say a head followed by a head is less than 50%. In the next post you say all flips are 50/50. Which is it?
Look at the bottom of this image:
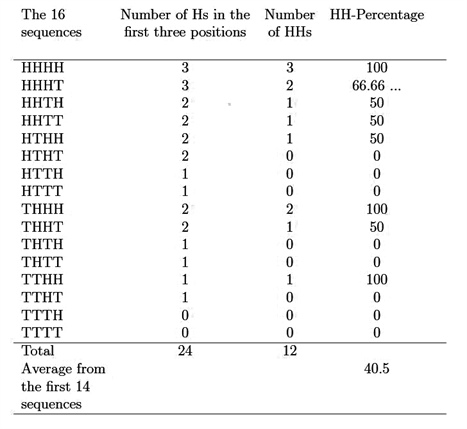
Notice the sum is 12 HHs and there are 24 H's in the first 3. What is 12/24? Hint: it's 0.5 AKA 50%.
The chart shows that the "head after heads" unweighted average after a "conditional sequence" (ie when one or more head occurs in the first 3 positions) is approx. 40.5% (hence the number in the "HH percentage "column).
Maybe read the original article and the academic paper https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2627354 that started all this.
Or the other links the article contained in this thread.
And yes, of course, we all agree a fair coin is 50/50 for any random flip. That was never in dispute.
***I'm here more to learn than teach that's for sure. I, and apparently others on the Internet, think this is interesting. I have no motives other than discourse.
Paper Abstract:
""
We prove that a subtle but substantial bias exists in a standard measure of the conditional dependence of present outcomes on streaks of past outcomes in sequential data. The magnitude of this novel form of selection bias generally decreases as the sequence gets longer, but increases in streak length, and remains substantial for a range of sequence lengths often used in empirical work. The bias has important implications for the literature that investigates incorrect beliefs in sequential decision making---most notably the Hot Hand Fallacy and the Gambler's Fallacy. Upon correcting for the bias, the conclusions of prominent studies in the hot hand fallacy literature are reversed..."
The 40.5% figure is simply wrong. I read the piles of sh** sources you keep posting (I have no idea why). It's wrong. That's it.
Better yet, can you show how the figure is ~40% and not 50%?
Here is an online argument I've found between a hedge fund guy and a stats prof. over these exact issues. http://andrewgelman.com/2016/02/18/miller-and-sanjurjo-share-5-tips-on-how-to-hit-the-zeitgeist-jackpot/
And here is the chart again below for those who want to interpret/explain further (maybe not needed).

Quote: RS......you CANNOT be serious.
The 40.5% figure is simply wrong. I read the piles of sh** sources you keep posting (I have no idea why). It's wrong. That's it.
Better yet, can you show how the figure is ~40% and not 50%?
HHHH : 1 means that for every time there was an H is the first 3 spots an H followed it 100% of the time. Thus 1 = 100% in this example.
HHHT: 2/3rd means 2 out of the 3 times or 66.666666%..... the qualifying H was followed by another H.
The .40 is the approx 40.5% probability after all the qualifying events were assessed.
Quote: DrawingDeadI think there's a simple one syllable word for what's been going on here, not with all that much subtlety and pretty much up in flashing neon lights, and not just in this thread... but I don't think I'm allowed to say it.
I think the word you refer to is 'Troll'
I know forum rule one forbids 'All personal insults' and I've seen cases where the accusation 'Troll' has been deemed to be such a personal insult. I don't agree with that implied extension to the rule, but hey, I don't set the rules or their interpretation.
So, Like DD, I will not accuse the OP of being a troll. I will not attack the writer, I will attack the writing:-
Every link, chart, table and bit of narrative that I've seen from the OP has been absurdly wrong and unsupportable. He refuses to desist in posting abject stupidity.
So, I'm going to block the OP, so as to no longer see his posts.
I also block Trolls..
Quote: bazooookaI still contend that there are event sequences where heads will be less than 50%.
Unless it is a biased coin, you are wrong. This is not even worthy of debate. Coins simply don't have a memory. Since the departure of AlanMendelson, you will probably not find anyone to take your side here on that.
If you think you can get 60% right flipping a coin, why don't you prove us all wrong by making millions using the same strategy betting red and black in roulette.
Quote: OnceDearI think the word you refer to is 'Troll'
I know forum rule one forbids 'All personal insults' and I've seen cases where the accusation 'Troll' has been deemed to be such a personal insult. I don't agree with that implied extension to the rule, but hey, I don't set the rules or their interpretation.
So, Like DD, I will not accuse the OP of being a troll. I will not attack the writer, I will attack the writing:-
Every link, chart, table and bit of narrative that I've seen from the OP has been absurdly wrong and unsupportable. He refuses to desist in posting abject stupidity.
So, I'm going to block the OP, so as to no longer see his posts.
I also block Trolls..
Watch yourself. This comes very close to crossing the line. The OP has at least been polite and seems to be honestly trying to debate this in a civil manner. I think an apology to the OP is in order.
Quote: WizardWatch yourself. This comes very close to crossing the line. The OP has at least been polite and seems to be honestly trying to debate this in a civil manner. I think an apology to the OP is in order.
Thanks Mike, I note your rebuke. I also acknowledge that the OP has been polite. I make no observation about his honesty or intent.
I unreservedly apologise for any offence caused to anyone by my post.
The OP remains blocked from my view and now I'm going to also block this thread. In fact, I'm going to self exclude from posting here for a week. Thank you OP.
Quote: bazooookaIt all adds up to around 40% as shown in charts linked below. Flip sequences have different odds than individual flip outcomes.
https://sinews.siam.org/Portals/SiNews2/EasyDNNNews/thumbs/383/117HotHandsTable.JPG
The problem with the chart is, it treats every one of the 14 sets of four flips (besides TTTH and TTTT) equally in terms of counting HHs versus HTs.
Look at the first two columns of numbers - this tells you all you need to know; of the 24 situations where there is an H in one the first 3 positions, 12 of them have that H followed by another H, and 12 have the same H followed by a T.
1. You encounter a system that you are certain is random. For this case, the previous outcomes have no predictive power over what will happen in the future.
2. Real-life systems. If one observes 100 consecutive coin flips that all come up heads, then one should feel fairly confident that the 101st coin flip will be heads as well - because what one has probably discovered is that the coin flip is not random. Maybe the coin is weighted, maybe there are magnets involved, maybe the person performing the flip has practiced so as to manipulate the coin - all of those explanations are arguably more probable than than the assumption that the coin flip is random but 100 coin flips just happened to have the same result.
All mechanical objects experience "wear" and surface alteration with time and most materials experience inelastic deformation over time. Solid objects are always inhomogeneous to some degree with variations in density throughout the object and small imprecision in dimensions, squareness or roundness/curvature. These things can cause mechanical systems to depart from randomness.
And human operators of gambling systems are capable of insincerity, particularly when they are motivated by self-interest.
So, no matter what the mathematicians say, it is wise for players to keep their eyes open and take note of hot streaks and cold streaks because they may signify the game is not random ( and at worst, that it is rigged.). That's exactly what casino security does - and players should do it too.
Read the link below where a statistics professor explains this to a hedge fund guy who ultimately concedes the point. We're not talking about biased coins. This is a restricted choice issue and more similar to a Monty Hall type problem,
And, yes, there is no way to make money with this unless one were to propose a similar bet (as happened in the below post).
http://andrewgelman.com/2016/02/18/miller-and-sanjurjo-share-5-tips-on-how-to-hit-the-zeitgeist-jackpot/

I like where you're heading Mike. This is where I was going to go too. Once a conversation reaches this point, it's time for practicality and put up or shut up in my opinion:Quote: WizardUnless it is a biased coin, you are wrong. This is not even worthy of debate. Coins simply don't have a memory. Since the departure of AlanMendelson, you will probably not find anyone to take your side here on that.
If you think you can get 60% right flipping a coin, why don't you prove us all wrong by making millions using the same strategy betting red and black in roulette.
bazooooka... I'll bring a fair coin (quarter) that you can inspect to ensure you believe it's fair. We'll toss the coin 10,000 times (or more) and you have to call the heads/tails correctly. You're stating that you can get 60% right... so after 10,000 flips if you're 60% or higher you win. If you've called the flip INCORRECTLY > 40% then you lose. I'd be willing to bet 10's of thousands of dollars. If you truly believe in this paper, and that you have an edge, this should be just free money to you.
What say you? Put up some real money and put this to a REAL test? Otherwise it's quite obvious that this is all just word fluff and we can all move on with our lives.
Quote: bazooookaWiz,
Read the link below where a statistics professor explains this to a hedge fund guy who ultimately concedes the point. We're not talking about biased coins. This is a sampling issue and more similar to a Monty Hall type problem,
The Monty Hall paradox is famous, and, like the article you linked to, shows how introducing bias will lead to incorrect conclusions.
You can challenge the paper's author yourself . In fact someone else did exactly that. How the bet is structured matters here. This is not about a fair coin or 50/50 expectations.
http://andrewgelman.com/2016/02/18/miller-and-sanjurjo-share-5-tips-on-how-to-hit-the-zeitgeist-jackpot/
"Entanglement is what Einstein referred to as �spooky action at a distance.� It�s a phenomenon by which one particle can effectively �know� something about another particle instantaneously, even if those two particles are separated by a great distance"
the author of this article might be stretching with this one, but nonetheless here it is:
"Particles can�t be alive or dead, so instead think heads and tails. If you flip a coin 100 times, odds are it will come up heads close to 50 times and tails close to 50 times. If I then flip my own coin 100 times, there�s a high probability the split will also be close to 50/50. But if our coins are entangled, then the outcome of your flip determines the outcome of my flip � perhaps our entanglement is such that every time you flip heads I flip tails. If we flip our coins enough times, our entanglement will begin to become obvious, because my outcome of my flip is no longer random, but determined by your flip, and the odds of my flipping tails every time you flip heads get lower and lower the more we flip."
And please, I AM NOT IN ANY WAY SUGGESTING THAT THIS IDEA CAN GIVE YOU ANY KIND OF EDGE IN GAMBLING.
but to me, it is a fascinating article and makes me wish i was a lot smarter than i am to be able to get deeper into it.
http://www.cbsnews.com/news/600-year-old-starlight-bolsters-einsteins-spooky-action-at-a-distance/
Quote: OnceDearThanks Mike, I note your rebuke. I also acknowledge that the OP has been polite. I make no observation about his honesty or intent.
I unreservedly apologise for any offence caused to anyone by my post.
The OP remains blocked from my view and now I'm going to also block this thread. In fact, I'm going to self exclude from posting here for a week. Thank you OP.
Although you won't read this, I'd like to say you're very much the gentlemen. Enjoy your week off.
Quote: bazooooka
The answer is 1/3.
Quote: lilredroosterthere is a fascinating scientific concept of "entanglement".
Quantum entanglement (Verschränkung) deals with sub-atomic particles. It can also work across light years of distance. In no way would it relate to cards.
OK, who's going to bring up Schrödinger's cat?
Quote: QFITQuantum entanglement (Verschränkung) deals with sub-atomic particles. It can also work across light years of distance. In no way would it relate to cards.
just to be clear, i never implied that it had anything to do with cards.
That cat's been in that box for over 100 years. Let's just all agree the damn thing is dead already... =PQuote: QFIT...OK, who's going to bring up Schrödinger's cat?
Same rules/setup again as posed in the image and the contestant pick door 3 again: But suppose a case where "door 1" or "door 2" or "both" can have a head. If "both" Monty will randomly open one of the two. We can't see which one but we know that he has done so thus signaling there is at least 1 head within the first two doors.
*This restriction provides info similar to the other heads followed by heads coin examples earlier in this thread.*
**"Finite" sequences have dynamic odds as events/doors/flips etc unfold and intuition doesn't usually help most**
Questions (for anyone):
How many door sequences now exist with the info that for sure either door 1, or door 2, or both, have a head?
What's the odds of seeing another head if we open the next door to the right of whatever door Monty opened (either door 2 or 3)?
Quote: WizardQuote: bazooooka
The answer is 1/3.
The insight from this question is why the finite sequence sampled in the coin tosses earlier in this thread end up being less than 50%.
"""Same rules/setup again as posed in the image and the contestant pick door 3 again: But suppose a case where "door 1" or "door 2" or "both" can have a head. If "both" Monty will randomly open one of the two. We can't see which one but we know that he has done so thus signaling there is at least 1 head within the first two doors."""
FYI: To figure this out layout all the possible door outcomes visually and you will see it's less than 50% once we are restricted to the knowledge that Monty only opens doors if they have a head. We know he has done so but we don't know if it is door 1 or door 2.
Some scientific studies were seriously flawed because of poor PRNGs.Quote: QFITCasinos go through extraordinary effort to ensure randomness. Failure to do so would cost them dearly. Humans looking for patterns will nearly always find patterns that don't exist.
Casinos (and game designers) often fail in their efforts. APs often try to find & exploit these failures.
Recently one casino host told me about a mis-set slot machine where a pair of people made six figures in one day before the problem was spotted.
I've heard of other mis-set slot machines which have cost the VP Slots his job...because of six-figure losses.
------
It doesn't matter that "casinos go through extraordinary effort to ensure randomness", it's that players may need to protect themselves.
Most "must-hit" progressive slot machines in the past decade have had a uniform distribution of progressive drop points (e.g. a $50 progressive starting at $25 has an equal chance of dropping anywhere between 25 and 50).
However, CJ has released very popular progressives which are programmed to fall very close to the must-hit point (maybe 92-96% towards the top).
So in this case, it's not a question of "random", but "WHICH KIND oF RANDOM"?
e.g. what is the distribution?
-----
https://en.wikipedia.org/wiki/Statistical_randomness
A numeric sequence is said to be statistical random when it contains no recognizable patterns or regularities; sequences such as the results of an ideal dice roll, or the digits of π exhibit statistical randomness.
Statistical randomness does not necessarily imply "true" randomness, i.e., objective unpredictability. Pseudorandomness is sufficient for many uses, such as statistics, hence the name statistical randomness.
Legislation concerning gambling imposes certain standards of statistical randomness to slot machines.
Global randomness and local randomness are different. Most philosophical conceptions of randomness are global�because they are based on the idea that "in the long run" a sequence looks truly random, even if certain sub-sequences would not look random. In a "truly" random sequence of numbers of sufficient length, for example, it is probable there would be long sequences of nothing but repeating numbers, though on the whole the sequence might be random.
Local randomness refers to the idea that there can be minimum sequence lengths in which random distributions are approximated. Long stretches of the same numbers, even those generated by "truly" random processes, would diminish the "local randomness" of a sample (it might only be locally random for sequences of 10,000 numbers; taking sequences of less than 1,000 might not appear random at all, for example).
Over the history of random number generation, many sources of numbers thought to appear "random" under testing have later been discovered to be very non-random when subjected to certain types of tests. The notion of quasi-random numbers was developed to circumvent some of these problems, though pseudorandom number generators are still extensively used in many applications (even ones known to be extremely "non-random"), as they are "good enough" for most applications.
https://en.wikipedia.org/wiki/Randomness_tests
The use of an ill-conceived random number generator can put the validity of an experiment in doubt by violating statistical assumptions. Though there are commonly used statistical testing techniques such as NIST standards, Yongge Wang showed that NIST standards are not sufficient. Furthermore, Yongge Wang [4] designed statistical�distance�based and law�of�the�iterated�logarithm�based testing techniques. Using this technique, Yongge Wang and Tony Nicol [5] detected the weakness in commonly used pseudorandom generators such as the well known Debian version of OpenSSL pseudorandom generator which was fixed in 2008.
Quote: TotheseaGambling "experts" see everything in black and white, and find any challenge to the house edge simply hilarious. They'll learn better one day. Meanwhile, know that winning comes in shades of green, not grey!
No idea where you got that idea. The variables in gaming are massive. My most common response to simple questions is: "it depends". Nonetheless, if the observations are always exactly 50/50, that's not random